
Google’s new Gemini AI model is getting a mixed reception after its big debut yesterday, but users may have less confidence in the company’s tech or integrity after finding out that the most impressive demo of Gemini was pretty much faked.
A video called “Hands-on with Gemini: Interacting with multimodal AI” hit a million views over the last day, and it’s not hard to see why. The impressive demo “highlights some of our favorite interactions with Gemini,” showing how the multimodal model (i.e., it understands and mixes language and visual understanding) can be flexible and responsive to a variety of inputs.
To begin with, it narrates an evolving sketch of a duck from a squiggle to a completed drawing, which it says is an unrealistic color, then evinces surprise (“What the quack!”) when seeing a toy blue duck. It then responds to various voice queries about that toy, then the demo moves on to other show-off moves, like tracking a ball in a cup-switching game, recognizing shadow puppet gestures, reordering sketches of planets, and so on.
It’s all very responsive, too, though the video does caution that “latency has been reduced and Gemini outputs have been shortened.” So they skip a hesitation here and an overlong answer there, got it. All in all, it was a pretty mind-blowing show of force in the domain of multimodal understanding. My own skepticism that Google could ship a contender took a hit when I watched the hands-on.
Just one problem: The video isn’t real. “We created the demo by capturing footage in order to test Gemini’s capabilities on a wide range of challenges. Then we prompted Gemini using still image frames from the footage, and prompting via text.” (Parmy Olson at Bloomberg was the first to report the discrepancy.)
So although it might kind of do the things Google shows in the video, it didn’t, and maybe couldn’t, do them live and in the way they implied. In actuality, it was a series of carefully tuned text prompts with still images, clearly selected and shortened to misrepresent what the interaction is actually like. You can see some of the actual prompts and responses in a related blog post — which, to be fair, is linked in the video description, albeit below the ” . . . more.”
On one hand, Gemini really does appear to have generated the responses shown in the video. And who wants to see some housekeeping commands like telling the model to flush its cache? But viewers are misled about the speed, accuracy, and fundamental mode of interaction with the model.
For instance, at 2:45 in the video, a hand is shown silently making a series of gestures. Gemini quickly responds, “I know what you’re doing! You’re playing Rock, Paper, Scissors!”

Image Credits: Google/YouTube
But the first thing in the documentation of the capability is how the model does not reason based on seeing individual gestures. It must be shown all three gestures at once and prompted: “What do you think I’m doing? Hint: It’s a game.” It responds, “You’re playing rock, paper, scissors.”
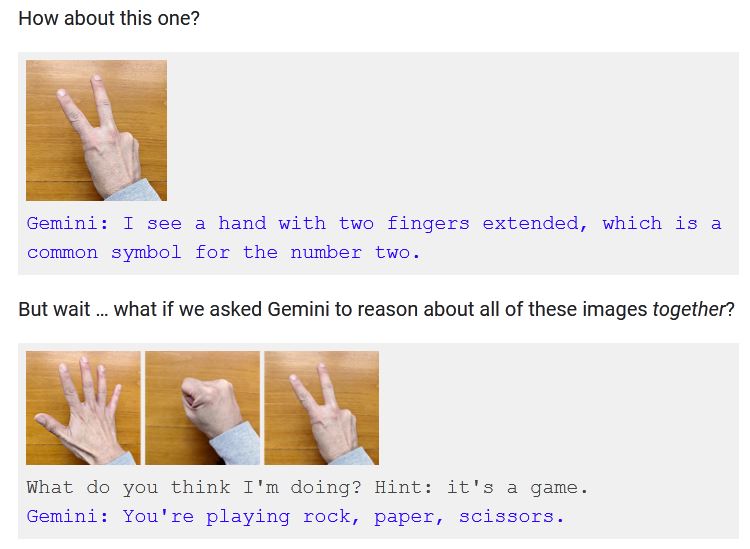
Image Credits: Google
Despite the similarity, these don’t feel like the same interaction. They feel like fundamentally different interactions, one an intuitive, wordless evaluation that captures an abstract idea on the fly, another an engineered and heavily hinted interaction that demonstrates limitations as much as capabilities. Gemini did the latter, not the former. The “interaction” showed in the video didn’t happen.
Later, three sticky notes with doodles of the sun, Saturn, and Earth are placed on the surface. “Is this the correct order?” Gemini says, “No, the correct order is Sun, Earth, Saturn.” Correct! But in the actual (again, written) prompt, the question is “Is this the right order? Consider the distance from the sun and explain your reasoning.”

Image Credits: Google
Did Gemini get it right? Or did it get it wrong and needed a bit of help to produce an answer they could put in a video? Did it even recognize the planets, or did it need help there as well?
In the video, a ball of paper gets swapped around under a cup, which the model instantly and seemingly intuitively detects and tracks. In the post, not only does the activity have to be explained, but also the model must be trained (if quickly and using natural language) to perform it. And so on.
These examples may or may not seem trivial to you. After all, recognizing hand gestures as a game so quickly is actually really impressive for a multimodal model! So is making a judgment call on whether a half-finished picture is a duck or not! Although now, since the blog post lacks an explanation for the duck sequence, I’m beginning to doubt the veracity of that interaction as well.
Now, if the video had said at the start, “This is a stylized representation of interactions our researchers tested,” no one would have batted an eye — we kind of expect videos like this to be half factual, half aspirational.
But the video is called “Hands-on with Gemini” and when they say it shows “our favorite interactions,” it implies that the interactions we see are those interactions. They were not. Sometimes they were more involved; sometimes they were totally different; sometimes they don’t really appear to have happened at all. We’re not even told what model it is — the Gemini Pro one people can use now, or (more likely) the Ultra version slated for release next year?
Should we have assumed that Google was only giving us a flavor video when they described it the way they did? Perhaps then we should assume all capabilities in Google AI demos are being exaggerated for effect. I write in the headline that this video was “faked.” At first I wasn’t sure if this harsh language was justified (certainly Google doesn’t think so; a spokesperson asked me to change it). But despite including some real parts, the video simply does not reflect reality. It’s fake.
Google says that the video “shows real outputs from Gemini,” which is true, and that “we made a few edits to the demo (we’ve been upfront and transparent about this),” which isn’t. It isn’t a demo — not really — and the video shows very different interactions from those created to inform it.
Update: In a social media post made after this article was published, Google DeepMind’s VP of Research Oriol Vinyals showed a bit more of how “Gemini was used to create” the video. “The video illustrates what the multimodal user experiences built with Gemini could look like. We made it to inspire developers.” (Emphasis mine.) Interestingly, it shows a pre-prompting sequence that lets Gemini answer the planets question without the sun hinting (though it does tell Gemini it’s an expert on planets and to consider the sequence of objects pictured).
Perhaps I will eat crow when, next week, the AI Studio with Gemini Pro is made available to experiment with. And Gemini may well develop into a powerful AI platform that genuinely rivals OpenAI and others. But what Google has done here is poison the well. How can anyone trust the company when they claim their model does something now? They were already limping behind the competition. Google may have just shot itself in the other foot.